
Vessel Segmentation and Artery-Vein Classification from Combined Retinal Fundus Images and Fluorescein Angiography
Noh K.J. Park S.J. Lee S.
Background
Retinal fundus images are the only type of medical image that directly observes the blood vessels to generate clear, high resolution visualizations. They are sim- ple, noninvasive, relatively cheap, and require no radiation or pharmaceuticals. But filamentary vessels are often barely visible in the retinal fundus image, even with zooming and contrast enhancement. We thus use corresponding fluorescein angiography (FA) images to provide consistent and detailed annotations at these regions. In FA, fluorescent dye is injected into the bloodstream to highlight the vessels by increasing contrast. By combining fundus images with FA, ground truth expert annotations for both vessel segmentation and artery-vein classification can be improved, which in turn can improve machine learning based methods.
Our Contribution Vessel Segmentation
We present a new framework for retinal vessel segmentation from fundus images through registration and segmentation of corresponding FA images. The proposed method can be compartmentalized into three subprocesses, cor- responding to 1) registration of FA frames and their vessel extraction, 2) multi- modal registration of aggregated FA vessels to the fundus image, 3) post-processing for fine refinement of the vessel mask.
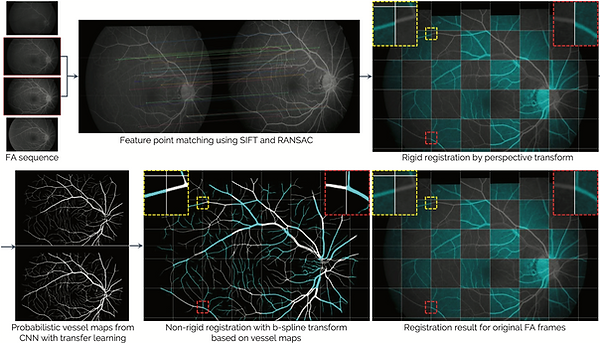
Figure 2. The registration framework for a pair of FA frames.

Figure 3. The registration framework for the aggregated FA vessel mask and fundus image.

Figure 4. The postprocessing framework comprising binarization and refinement.

Figure 5. Comparison between the results of the proposed method before and after self-training.
Results Vessel Segmentation
We show that the obtained results contain a considerable amount of filamentary vessels that are virtually indiscernible to the naked eye with only the color fundus image. We believe that these results conversely show the limitations of expert annotations as ground truth, which is the standard of all previously released public datasets. Nonetheless, since the proposed method may still contain errors, the requirement of expert annotation remains in order to designate data as ground truth.

Figure 1. Qualitative comparison between (a) manual expert annotations of DRIVE [14] and (b) the results of the proposed method with minimal manual editing of minor er- rors. Our goal is to construct a foundational dataset for achieving superhuman accuracy in deep learning based retinal vessel segmentation.

Table 1. Quantitative results of the proposed method together with the results obtained by SSANet trained on public fundus image datasets with expert annotated ground truth on our SNUBH F+FA dataset.

Table 2. Quantitative results obtained by SSANet trained on the SNUBH F+FA dataset with ground truth generated using the proposed method on public fundus image datasets.

Figure 5. Qualitative results. Six sample cases are shown in 3 × 2 formation, with (top) the original image, (middle) the results of the proposed method, and (bottom) vessel segmentation results of the SSANet [11] trained on the public HRF [3] dataset. Left and right columns shows the images in full and zoomed resolution, respectively.

Figure 6. Example illustrating the visibility of filamentary vessels in the fundus images.

Figure 10. Qualitative comparison of vessel extraction results on the HRF [7] test set. (a) The original image and (b) its ground truth expert annotations. Vessel extraction results by a SSANet (c) trained on the HRF training set and (d) trained on our SNUBH-F+FA dataset with ground truth generated based on the proposed method. (e,f) Zoomed portions of (a,b). (g,h) Zoomed portions of (c,d). (i) Results from applying histogram equalization to (e).
Our Contribution Artery-Vein Classification
Results for the various configurations of the FE-CNN are provided, as well as the results of FE-CNN with FA input only (FE-CNN-FA), FE-CNN with fun- dus image input only (FE-CNN-Fundus), and FE-CNN-Parallel combined with GCN rather than graph U-net (FE-CNN+GCN).

Figure 1. Visual overview of the proposed method with integrated feature extractor CNN for combined fundus image and FA input (FE-CNN) and hierarchical connectivity GNN (HC-GNN)

Figure 3. A visual description of the hierarchical connectivity graph neural network (HC-GNN) based on graph U-nets [6].
Results Artery-Vein Classification
Our main contribution is the development of a highly accurate novel A/V classification framework. It combines fundus image and FA sequence as input, with a customized feature extraction CNN configuration. An integrated hierar- chical GNN learns the high-level connectivity of vascular structures. We believe our method can be used to generate ground truth (GT) A/V masks with lit- tle manual editing. This can lead to a drastic increase in the training data for supervised learning of CNNs for fundus image inputs, thereby maximizing the potential of deep learning.
The proposed method comprises two main components, the feature extractor CNN (FE-CNN) for the fundus image and FA input and the hierarchical connectivity graph neural network (HC-GNN) for incorporating higher order connectivity into classification. For the FE-CNN, we empirically determine the optimal configu- ration, with the scale-space approximated CNN (SSANet) [16] as the backbone network. For the HC-GNN, we apply the graph U-net [6]. We term the proposed method as the fundus-FA hierarchical vessel graph network (FFA-HVGN).

Table 1. Quantitative results on our private DB. Results of our implementation of the multi-task method of Ma et al. [12] are provided for comparison. Sensitivity (Se), specificity (Sp), accuracy (Acc), and area-under-curve for the precision-recall curve (AUC-PR) and the receiver-operating-characteristic curve (AUC-ROC) are presented.
For comparative evaluation, we provide results of our implementation of the multi-task method of Ma et al. [12], which takes only the fundus image as input, without their multi-channel input. These results demonstrate that each component of the proposed method actually helps to improve the performance.

Table 2. Quantitative results on RITE A/V label DB [8]. Sensitivity (Se), specificity (Sp), accuracy (Acc) are presented.

Figure 4. Qualitative results. Four sample cases from our private DB are shown in 2 × 2 formation, with top to bottom rows illustrating (1) the original image, (2) GT, and results of (3) FE-CNN-Fundus (fundus image input only), (4) FE-CNN-Parallel (combined fundus-FA input), and (5) FFA-HVGN (proposed). Left and right columns show the images in full and zoomed resolution, respectively.
Paper
Vessel Segmentation
Fine-Scale Vessel Extraction in Fundus Images by Registration with Fluorescein Angiography. In: Shen D. et al. (eds) Medical Image Computing and Computer Assisted Intervention – MICCAI 2019. MICCAI 2019. Lecture Notes in Computer Science, vol 11764.
Noh K.J., Park S.J., Lee S.
Springer, Cham.
"Multimodal Registration of Fundus Images With Fluorescein Angiography for Fine-Scale Vessel Segmentation,"
K. J. Noh, J. Kim, S. J. Park and S. Lee
IEEE Access, vol. 8, pp63757-63769, 2020, doi: 10.1109/ACCESS.2020.2984372. [https://doi.org/10.1007/978-3-030-32239-7 86]
Artery-Vein Classification
Combining Fundus Images and Fluorescein Angiography for Artery/Vein Classification Using the Hierarchical Vessel Graph Network. In: Martel A.L. et al. (eds) Medical Image Computing and Computer Assisted Intervention – MICCAI 2020
Noh K.J., Park S.J., Lee S.
MICCAI 2020. Lecture Notes in Computer Science, vol 12265. Springer, Cham [https://doi.org/10.1007/978-3-030-59722-1 57]
collaboration
Developed in collaboration with researchers from [Seoul National University Bundang Hospital]